今天将从 CPU 的发展历程,来了解缓存一致性协议,Store Buffer, Store Forwarding, Invalidate Buffer, 可见性,重排序(Reorder),读屏障和写屏障
单核架构
计算机的两个核心部件: CPU 和内存。CPU 负责计算,内存负责存储指令以及指令所需的数据:
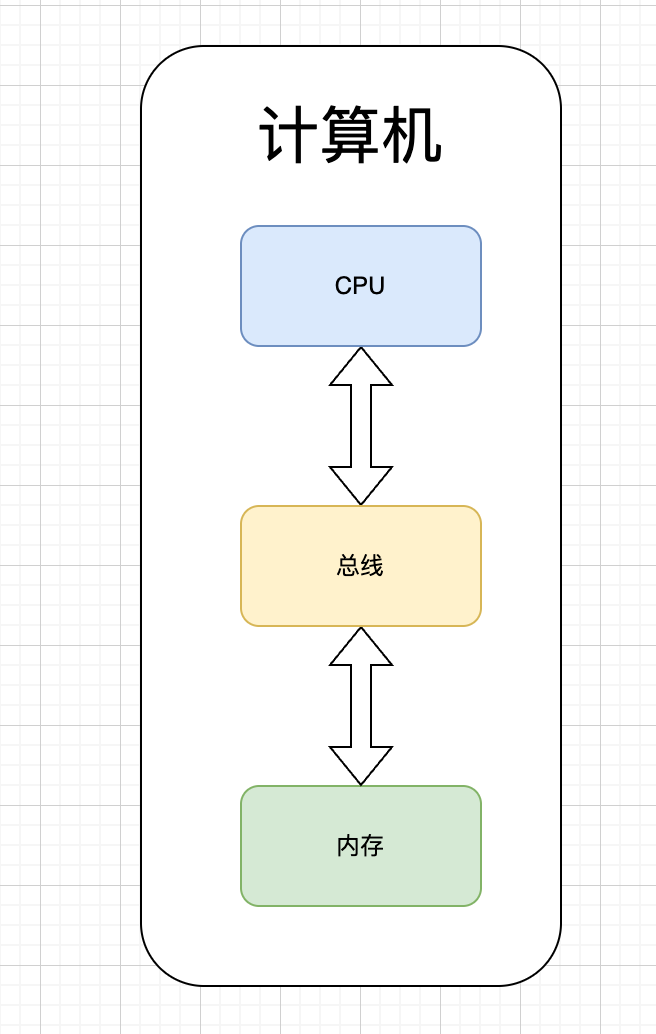
由于 CPU 的处理速度远远大于从内存获取数据的速度,因此工程师在内存和 CPU 之间加了一层缓存:
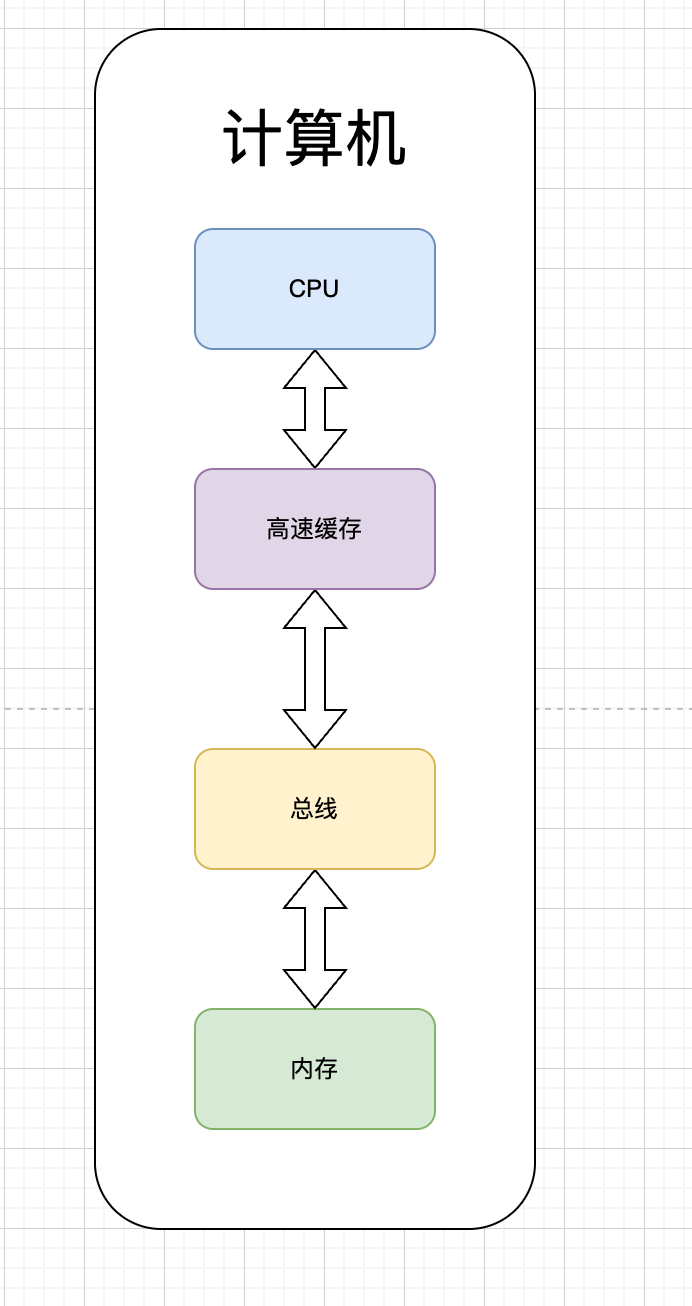
在单核 CPU 架构下,只能够通过提升 CPU 频率来提升性能,导致功耗急剧上升,从而出现了多核 CPU 架构。但是多核架构下需要处理一个问题,那就是缓存如何进行设计? 有两种方案:
- 多个 CPU 核心共享高速缓存
- 每个 CPU 核心管理自己的高速缓存
第一种方案实现比较简单,但是每个核心访问缓存之前需要获取访问缓存的权限,也就是锁,在获取到锁之前需要等待,等待期间会浪费很多 CPU 的性能。
第二种方案因为每个核心拥有自己的缓存,不需要获取锁,因此性能相对于第一种方案更高,这也是目前 CPU 使用的一种方案:
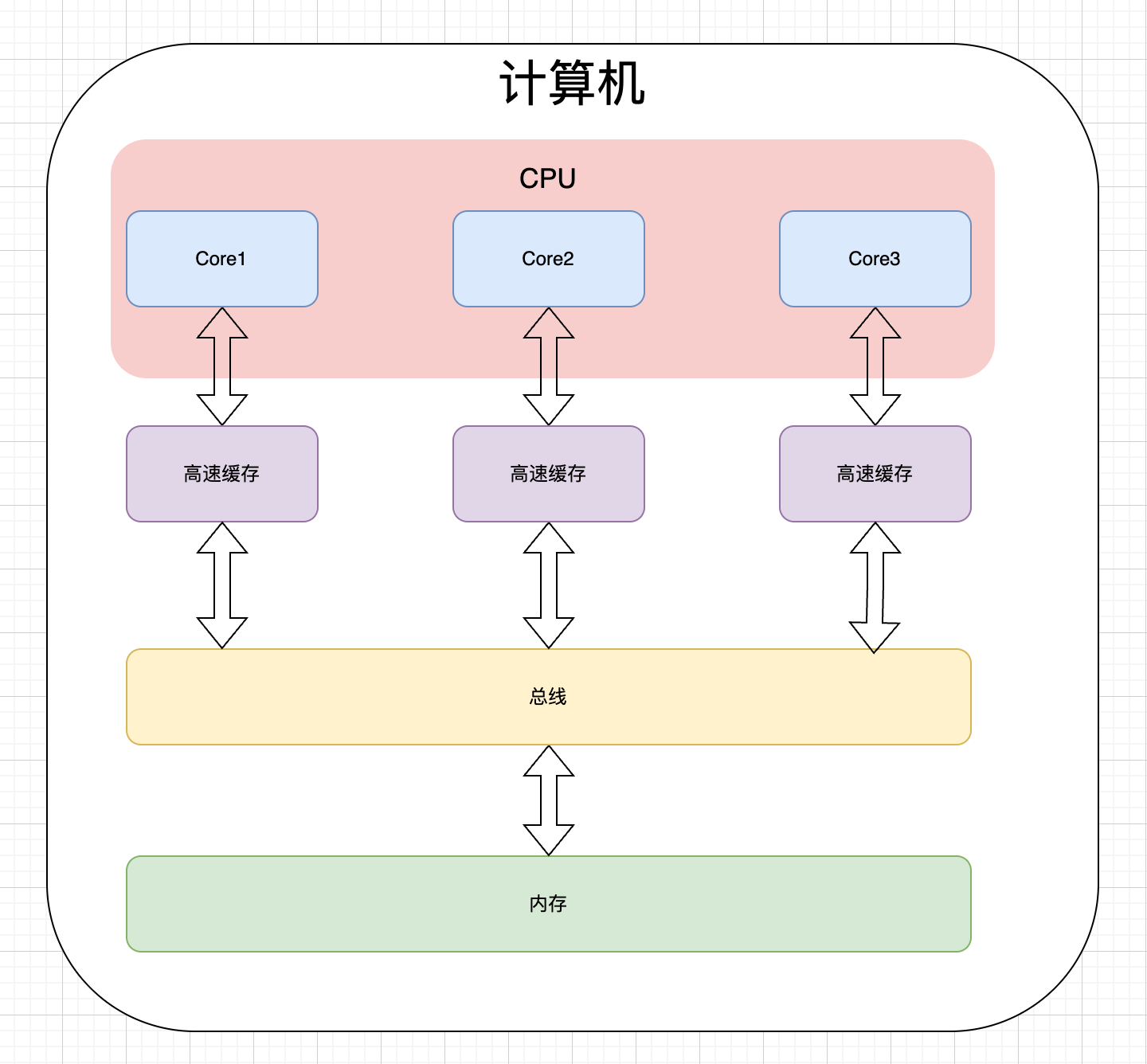
每个核心拥有自己的缓存,处于不同核心上的进程,因为进程 A 不能够修改进程 B 的数据,所以可以放心的修改各自缓存中的数据,但是如果同一个进程的多个线程分配在了不同的核心上,就不能够随意的修改各自缓存中的数据了。因为进程是资源分配的最小单位,同一个进程中的多个线程共享进程的资源,因此多线程环境下需要保证缓存的一致性。目前常用的缓存一致性协议是 MESI 协议。
MESI 协议
MESI(Modify, Exclusive, Shared, Invalid) 硬件缓存一致性协议确保所有核心看到的数据是一样的。在硬件层面实现了缓存一致性。
在缓存行中会有一个标志位表示当前缓存行的状态:
- M(Modified): 表示缓存行被修改过,是所有缓存中唯一有效(最新)的数据,还未写入内存,与内存中的数据不一致。
- E(Exclusive): 表示缓存数据未被修改,只在当前核心的缓存中存在,其他核心的缓存中不存在,是所有缓存中唯一的副本,与内存中的数据一致。
- S(Shared): 表示缓存行至少被 2 个核心缓存过,并且没有被修改,与内存中的数据保持一致。写缓存行之前,必须先让其他核心中的缓存行失效。
- I(Invalid): 表示缓存行无效,需要重新从内存或其他核心的缓存中加载最新的数据
在 MESI 协议下,核心 C1 写入缓存行 A 之前,需要通知其他的核心将缓存行 A 标记为无效,其他核心收到通知后,将缓存行 A 标记为无效,并需要给核心 C1 返回 ACK 确认,核心 C1 收到全部的 ACK 确认后才会更新缓存行 A,并将缓存行 A 的状态改成 Modifed。
sequenceDiagram
participant C1 as 核心 C1
participant C1C as C1 缓存
participant Bus as 总线
participant S2 as 核心 C2
participant S3 as 核心 C3
participant S4 as 核心 C4
C1->>Bus: 发送 "Invalidate A" 请求
Bus->>S2: 广播失效通知 (Invalidate A)
Bus->>S3: 广播失效通知 (Invalidate A)
Bus->>S4: 广播失效通知 (Invalidate A)
S2->>S2: 将 A 标记为无效
S3->>S3: 将 A 标记为无效
S4->>S4: 将 A 标记为无效
S2-->>Bus: 发送 ACK
S3-->>Bus: 发送 ACK
S4-->>Bus: 发送 ACK
Bus-->>C1: 所有 ACK 已收到
C1->>C1C: 写入缓存行 A,状态变为 Modified
通过上面的流程图可以看到,从发送 Invalidate 通知到最终修改缓存行这段期间,CPU 必须等待,这非常的浪费 CPU 的性能,因此工程师在 CPU 和缓存之间加了一个 Store Buffer
Store Buffer 和读写屏障
Store Buffer 的作用是将数据放入 Store Buffer 中,等收到全部的 ACK 之后,再将 Store Buffer 中的数据写入缓存中,这样 CPU 无需等待,继续执行其他的指令。CPU 获取数据数据时,每个 CPU 核心可以扫描自身的 Store Buffer, 但是不能够访问其他 CPU 核心的 Store Buffer。
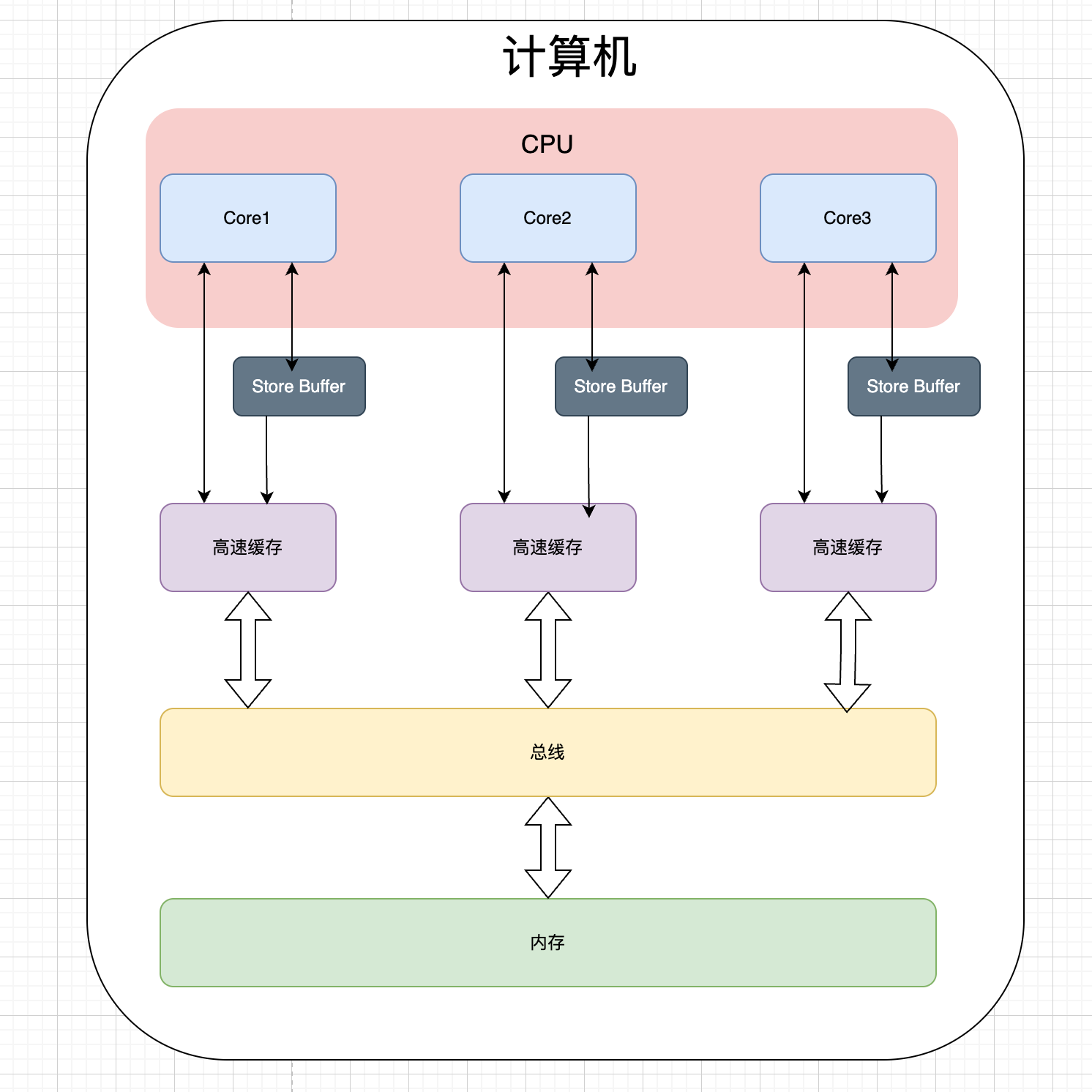
Store Forwarding
CPU 虽然可以不用等待,但是这样会将 Invalidate 操作变成了一个异步的行为,这带来了一个可见性问题,看下面的代码:
public class InvalidateTest{
private int a = 0;
private int b = 0;
public void foo() {
a = 1;
int b = a + 1;
System.out.println(b);
}
}
假设现在缓存行中存在 a = 0,状态是 Shared, 我们看一下执行过程:
- 执行 a = 1, 因为缓存行的状态是
Shared,所以需要通知其他的核心,将 a = 1 写入 Store Buffer 中,发送 Invalidate 通知,CPU 继续执行 - 执行
int b = a + 1;。读取缓存行中 a 的值,此时a = 0, 因此最后 b 的值为 1 而不是 2
之所以会出现上面的问题,是因为 CPU 没有读取 Store Buffer 中 a 的最新值,而是读取的缓存行中已经过期了的值,因此硬件工程师设计让 CPU 先读取 Store Buffer 中的内容,没有找到再读取缓存中的内容,这个过程叫做 Store Forwarding。
写屏障
public class InvalidateTest{
private int a = 0;
private int b = 0;
private int c = 0;
public void foo() {
a = 1;
b = 1;
}
public void boo() {
while(b == 0) continue;
assert(a == 1);
}
}
看下上面的代码: assert(a == 1) 一定会断言成功吗? 答案是不一定,看下下面的执行顺序:
假设核心 C1 执行 foo() 方法,核心 C2 执行 boo() 方法。C1 缓存中存在 a = 0, 状态是 Shared 和 b = 0, 状态是 Exclusive 独占状态,C2 缓存中存在 a = 0 状态是 Shared
- C1 执行
a = 1, 由于状态是Shared, 需要发送 Invalidate 通知并写入 Store Buffer - C1 执行
b = 1, 由于是Exclusive的状态,无需发送 Invalidate 通知,直接写入缓存行,并将状态修改成Modified - C2 执行
while循环,由于b不在缓存中,发出Read通知,C1 收到消息 Read 消息后,发现拥有b的最新版本,将b = 1发送给 C2, 并将b = 1的缓存行状态设置成Shared - C2 收到
b = 1后,同样将b = 1的缓存行状态设置成Shared,同时退出while循环 - C2 执行
assert(a == 1),由于缓存中存在a = 0,状态是Shared,并且此时还未收到a的 Invalidate 通知,因此a == 1断言失败 - C2 接收到 C1 关于 a 的 Invalidate 通知
根据上面的执行流程就好像: b = 1 先于 a = 1 执行,这就是所谓的乱序执行(Reorder)。从单个核心上来看,执行的顺序并没有变,由于 Invalidate 通知是一个异步操作,如果消息通知的不够及时,就会导致一个乱序问题的操作。
这个问题该怎么解决呢? 答案是写屏障,写屏障的作用: 写屏障之后的写缓存操作执行之前, 必须先将 Store Buffer 中的写操作先同步到缓存中。
如果写屏障是要等 Invalidate ACK,那就又回到了没有 Store Buffer 的场景。现代 CPU,写屏障的实现方式是强制将写屏障之后的写操作全部写入 Store Buffer, 而不能直接写缓存,这样一个个的排队就不会出现上述的乱序问题了。
Invalidate Buffer 和读屏障
通过 Store Buffer 和 Store Forwarding 虽然解决了可见性问题,如果写缓存的操作非常多,Invalidate ACK 回复的又非常慢,导致 Store Buffer 很快就被填满,CPU 就又只能够等待 Store Buffer 可用,硬件工程师为了解决 ACK 回复慢的问题,引入了 Invalidate Buffer。
核心收到 Invalidate 通知后,立马回复 Invalidate ACK, 并将 Invalidate 操作写入 Invalidate Buffer 中。
获取数据时,CPU 核心不能够扫描 Invalidate Buffer 来判断缓存是否 Invalidate(过期)
同样的,引入 Invalidate Buffer 将 Invalidate 操作变成了异步操作,也是会导致一个可见性问题,看下面的代码:
public class InvalidateTest{
private int a = 0;
private int b = 0;
private int c = 0;
public void foo() {
a = 1;
int b = a + 1;
System.out.println(b);
}
public void boo() {
int c = a + 1;
System.out.println(b);
}
}
假设核心 C1 执行 foo() 方法,核心 C2 执行 boo() 方法。C1 和 C2 的缓存行中都存在 a = 0;
- C1 执行
a = 1, 发送 Invalidate 通知给 C2 - C2 收到 Invalidate 通知后立马回复 ACK, 并将 Invalidate 操作写入 Invalidate Buffer
- C2 执行
int c = a + 1的操作,由于 Invalidate 操作还在 Invalidate Buffer 中,还未执行,因此变量 a 所在的缓存行生效,a 的值为 0,最后 b 的值为 1
如果没有 Invalidate Buffer, C2 需要现将 a 所在的缓存行标记为过期,再回复 ACK, 这样执行 int c = a + 1 的时候,a 所在的缓存行已经过期,C2 需要读取 a 的最新值。
那怎么解决这个可见性的问题呢? 答案是读屏障,读屏障的作用是将 Invalidate Buffer 中的指令全部执行完之后才会继续执行读屏障后的指令,通过读屏障,就可以解决解决 Invalidate Buffer 带来的可见性问题了。
可见性
invalidate buffer 将 invalidate(过期/失效) 指令放入 invalidate buffer,并立即回应 invalidate ack。CPU 在真正执行 invalidate 指令之前的空档期,如果读取了本应该已经过期但是实际上没有过期的缓存行就会出现可见性的问题。
invalidate 指令的作用是将某个缓存行标记为过期,标记缓存行里面的数据是旧的,不是最新的数据,需要重新从内存或缓存中读取最新的数据,但是 invalidate 指令被放入 Invalidate Buffer 中延迟执行,在 invalidate 指令执行之前又出现了读本应该过期的缓存行,就出现了读取旧值,而非最新值的情况,从而出现了可见性问题。